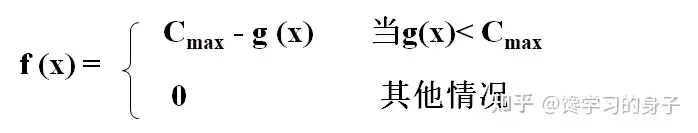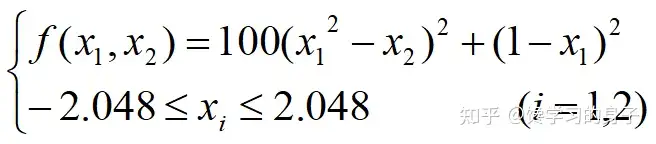事情是这样的,压根没学过什么人工智能相关课程的笔者收到了这样一份小组作业:
于是不得不从网上找结局方案(其实就是想吃现成的),发现遗传算法似乎不是很难,而且代码量也不大,而笔者的python又学的好凑合,便决定来用python实现遗传算法,来完成这一小组作业
遗传算法简介 遗传算法简称GA(Genetic Algorithms)模拟自然界生物遗传学(孟德尔)和生物进化论(达尔文)通过人工方式所构造的一类并行随机搜索最优化方法,是对生物进化过程“优胜劣汰,适者生存”这一过程进行的一种数学仿真。
其实说白了,这玩意其实大家在高中就接触过了,孟德尔的豌豆实验,摩尔根果蝇实验,本质上都是一种遗传算法的实现(这么说其实不太准确,爸爸像儿子了属于是),基本思路就是复制-挑选-迭代-挑选-迭代······
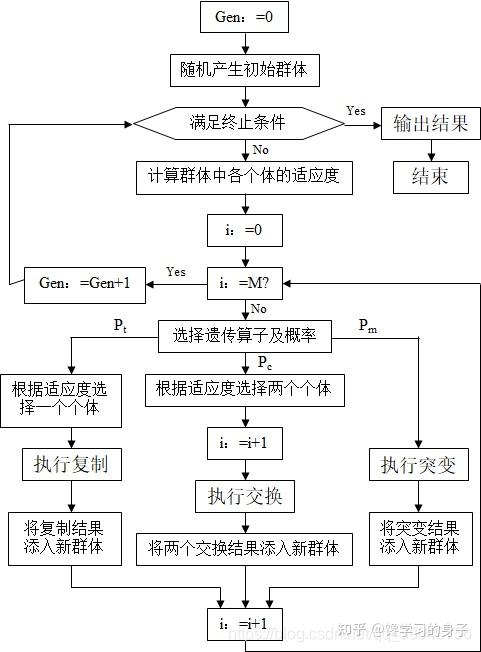
算法特点 直接对结构对象进行操作,不存在求导和函数连续性的限定; 具有内在的隐含并行性和更好的全局寻优能力; 采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。 算法流程 如图:
遗传算法主要执行以下四步:
随机地建立由字符串组成的初始群体; 计算各个体的适应度; 根据遗传概率,利用下述操作产生新群体:复制。将已有的优良个体复制后添入新群体中,删除劣质个体; 交换。将选出的两个个体进行交换,所产生的新个体添入新群体中。 突变。随机地改变某一个体的某个字符后添入新群体中。 反复执行(2)、(3)后,一旦达到终止条件,选择最佳个体作为遗传算法的结果。 算法实例 求f(x) = $x^2$ 极大值问题,设自变量 x 介于0~31,求其二次函数的最大值,即:max f(x) = $x^2$, x∈ [0, 31]
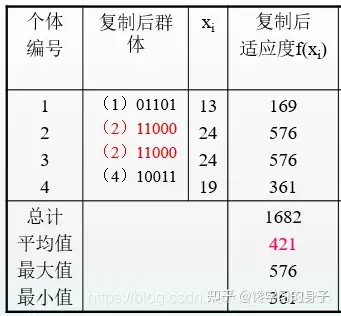
(1)编码 遗传算法首先要对实际问题进行编码,用字符串表达问题。这种字符串相当于遗传学中的染色体。每一代所产生的字符串个体总和称为群体。为了实现的方便,通常字符串长度固定,字符选0或1。 本例中,利用5位二进制数表示x值,采用随机产生的方法,假设得出拥有四个个体的初始群体,即:01101,11000,01000,10011。x值相应为13,24,8,19。
个体编号 初始群体 Xi 1 01101 13 2 11000 24 3 01000 8 4 10011 19
(2)计算适应度 衡量字符串(染色体)好坏的指标是适应度,它也就是遗传算法的目标函数。本例中用$x^2$计算。
个体编号 初始群体 Xi 适应度f(Xi) f(Xi)/Εf(Xi) f(Xi)/f Mp 1 01101 13 169 0.14 0.58 1 2 11000 24 576 0.49 1.97 2 3 01000 8 64 0.06 0.22 0 4 10011 19 361 0.31 1.23 1 总计Σf(Xi) 1170 1.00 4.00 4 平均值f 293 0.25 1.00 1 最大值 576 0.49 1.97 2 最小值 64 0.06 0.22 0
表中还列出了当前适应度的总和$∑f(x_i)$及平均值f
表中第6列的 f(xi)/f 表示每个个体的相对适应度,它反映了个体之间的相对优劣性。如2号个体的 f(xi)/f 值最高(1.97),为优良个体,3号个体最低(0.22),为不良个体。
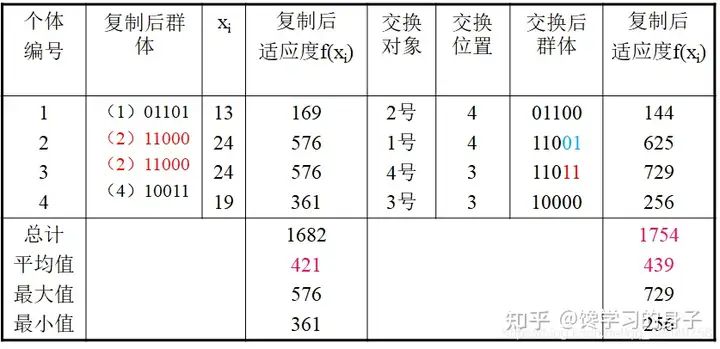
(3)复制 根据相对适应度的大小对个体进行取舍,2号个体性能最优,予以复制繁殖。3号个体性能最差,将它删除,使之死亡,表中的M表示传递给下一代的个体数目,其中2号个体占2个,3号个体为0,1号、4号个体保持为1个。这样,就产生了下一代群体
复制后产生的新一代群体的平均适应度明显增加,由原来的293增加到421 (4)交换 利用随机配对的方法,决定1号和2号个体、3号和4号个体分别交换,如表中第5列。再利用随机定位的方法,确定这两对母体交叉换位的位置分别从字符长度的第4位及第3位开始。如:3号、4号个体从字符长度第3位开始交换。交换开始的位置称交换点
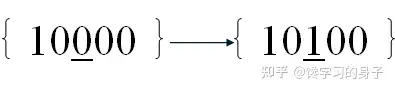
(5)突变 将个体字符串某位符号进行逆变,即由1变为0或由0变为1。例如,下式左侧的个体于第3位突变,得到新个体如右侧所示。
遗传算法中,个体是否进行突变以及在哪个部位突变,都由事先给定的概率决定。通常,突变概率很小,本例的第一代中就没有发生突变。
上述(2)~(5)反复执行,直至得出满意的最优解。
综上可以看出,遗传算法参考生物中有关进化与遗传的过程,利用复制、交换、突变等操作,不断循环执行,逐渐逼近全局最优解。
算法实现 (1)编码与解码 将不同的实数表示成不同的0,1二进制串表示就完成了编码,因此我们并不需要去了解一个实数对应的二进制具体是多少,我们只需要保证有一个映射能够将十进制的数编码为二进制即可。而在最后我们肯定要将编码后的二进制串转换为我们理解的十进制串,所以我们需要的是y = f ( x )的逆映射,也就是将二进制转化为十进制,也就是解码,十进制与二进制相互映射的关系以下为例进行说明: 例如 :对于一个长度为10的二进制串,如[0,0,0,1,0,0,0,0,0,1],将其映射到[1,3]这个区间 1. 首先将二进制数按权展开:$0 2^9+02^8+02^7+12^6+02^5+02^4+02^3+02^2+02^1+12^0=65$ 2. 然后将其压缩到区间[0,1]:$65/(2^{10} - 1) \approx0.0635386$ 3. 最后将[0,1]区间的数映射到我们想要的区间[1,3]:$0.0635386*(3-1)+ 1\approx1.12707722$,可以看出规律为:num * (high-low)+low 其中num为[0,1]之间的数对应此处的0.0635386,high和low表示我们想要映射的区间的上边界和下边界,分别对应此处的3和1。
现在再来看看编码过程。不难看出上面我们的DNA(二进制串)长为10,10位二进制可以表示$2^{10}$种不同的状态,可以看成是将最后要转化为的十进制区间 [ 1 , 3 ] 切分成$2^{10}$份。可看出,如果我们增加二进制串的长度,那么我们对区间的切分可以更加精细,转化后的十进制解也更加精确。所以DNA长度越长,解码为10进制的实数越精确
另外需要注意的是一个基因可能存储了多个数据的信息,在进行解码时注意将其分开,如一个基因含有x,y两个数据,该基因型的长度为20,可以用前10位表示x,后10位表示y,解码时分开进行解码。
(2)适应度 在实际问题中,有时希望适应度越大越好(如赢利、劳动生产率),有时要求适应度越小越好(费用、方差)。为了使遗传算法有通用性,这种最大、最小值问题宜统一表达。通常都统一按最大值问题处理,而且不允许适应度小于0。 对于最小值问题,其适应度按下式转换:
(3)选择 有了适度函数,然后就可以根据某个基因的适应度函数的值与所有基因适应度的总和的比值作为选择的依据,该值大的个体更易被选择,可以通过有放回的随机采样来模拟选择的过程,有放回的随机采样的方式可以参考我的这篇博客: 随机采样 (4)交叉和变异 交叉和 变异都是随机发生的,对于交叉而言,随机选择其双亲,并随机选择交叉点位,按照一定的概率进行交叉操作。可以通过以下方式实现:首先选择种群中的每个基因作为父亲,然后通过产生一个[0,1]随机数,将其与定义的交叉概率比较,如果小于该数,则在种群中随机选择另外的母亲,随机选择交叉点位进行交叉。 (5)举例 利用遗传算法求Rosenbrock函数的极大值
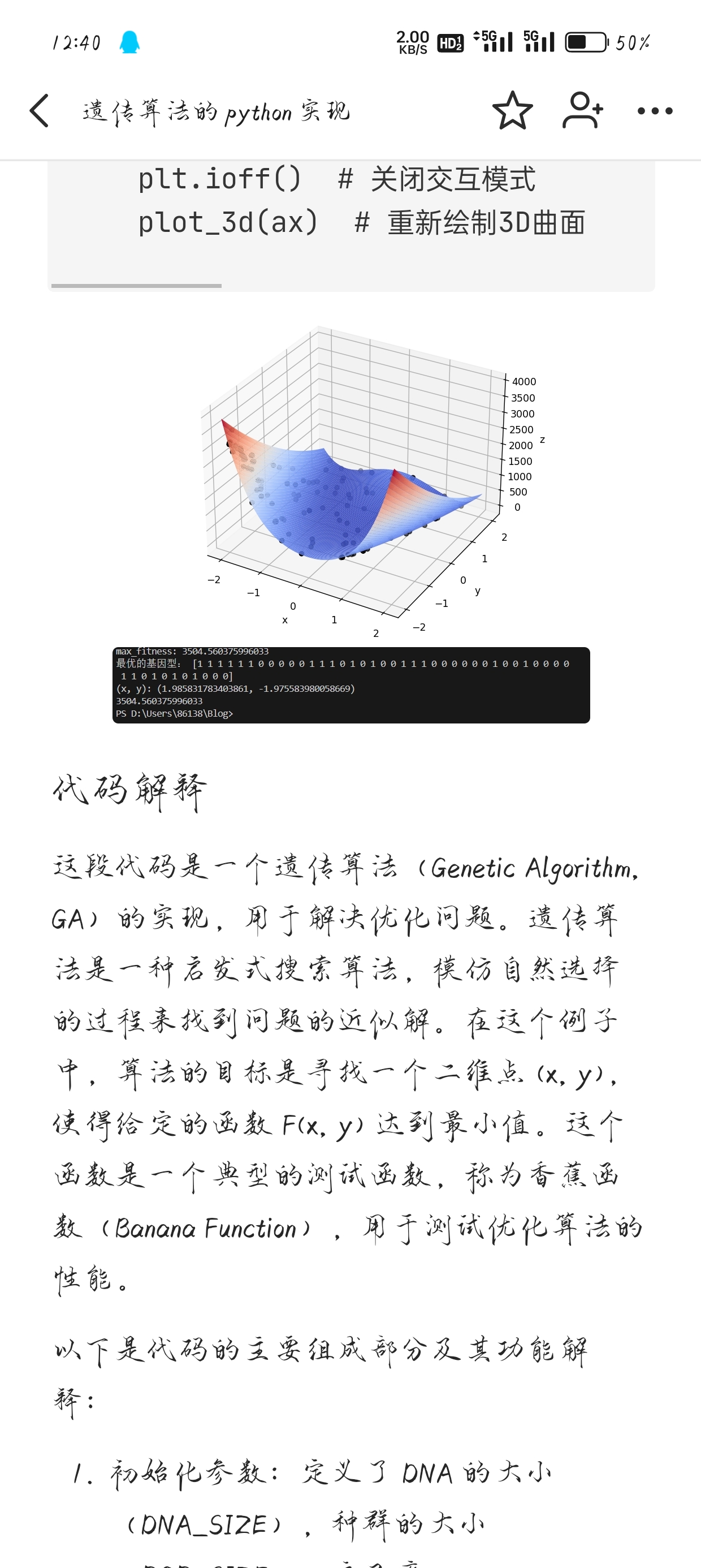
算法源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 import numpy as np # 导入numpy库,用于数学运算 import matplotlib.pyplot as plt # 导入matplotlib的pyplot模块,用于绘图 from matplotlib import cm # 导入matplotlib的颜色映射模块 from mpl_toolkits.mplot3d import Axes3D # 导入3D绘图工具 # 定义遗传算法的参数 DNA_SIZE = 24 # DNA的长度,即染色体的位数 POP_SIZE = 80 # 种群的大小,即染色体的数量 CROSSOVER_RATE = 0.6 # 交叉率,表示种群中有多少比例的个体会进行交叉操作 MUTATION_RATE = 0.01 # 变异率,表示基因突变的概率 N_GENERATIONS = 100 # 进化的代数 X_BOUND = [-2.048, 2.048] # x的取值范围 Y_BOUND = [-2.048, 2.048] # y的取值范围 # 定义目标函数,即优化问题中的函数 def F(x, y): return 100.0 * (y - x ** 2.0) ** 2.0 + (1 - x) ** 2.0 # 定义3D绘图函数 def plot_3d(ax): X = np.linspace(*X_BOUND, 100) # 生成x的等差数列 Y = np.linspace(*Y_BOUND, 100) # 生成y的等差数列 X, Y = np.meshgrid(X, Y) # 生成网格 Z = F(X, Y) # 计算每个点的函数值 ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap=cm.coolwarm) # 绘制3D曲面 ax.set_xlabel('x') # 设置x轴标签 ax.set_ylabel('y') # 设置y轴标签 ax.set_zlabel('z') # 设置z轴标签 plt.pause(3) # 暂停3秒 plt.show() # 显示图形 # 适应度函数,用于评估个体的适应度 def get_fitness(pop): x, y = translateDNA(pop) # 将DNA转换为x, y坐标 pred = F(x, y) # 计算适应度 return pred # DNA转换函数,将二进制编码的DNA转换为实数解 def translateDNA(pop): x_pop = pop[:, 0:DNA_SIZE] # 提取x坐标的DNA部分 y_pop = pop[:, DNA_SIZE:] # 提取y坐标的DNA部分 x = x_pop.dot(2 ** np.arange(DNA_SIZE)[::-1]) / float(2 ** DNA_SIZE - 1) * (X_BOUND[1] - X_BOUND[0]) + X_BOUND[0] y = y_pop.dot(2 ** np.arange(DNA_SIZE)[::-1]) / float(2 ** DNA_SIZE - 1) * (Y_BOUND[1] - Y_BOUND[0]) + Y_BOUND[0] return x, y # 交叉和变异函数 def crossover_and_mutation(pop, CROSSOVER_RATE=CROSSOVER_RATE): new_pop = [] # 初始化新的种群 for father in pop: # 遍历种群中的每一个个体 child = father.copy() # 复制个体作为孩子的初始基因 if np.random.rand() < CROSSOVER_RATE: # 以交叉率的概率进行交叉 mother = pop[np.random.randint(POP_SIZE)] # 随机选择另一个个体作为母亲 cross_points = np.random.randint(low=0, high=DNA_SIZE * 2) # 随机选择交叉点 child[cross_points:] = mother[cross_points:] # 孩子继承母亲的基因 mutation(child) # 对孩子进行变异 new_pop.append(child) # 将新个体添加到新种群中 return np.array(new_pop) # 返回新的种群 # 变异函数 def mutation(child, MUTATION_RATE=MUTATION_RATE): if np.random.rand() < MUTATION_RATE: # 以变异率的概率进行变异 mutate_point = np.random.randint(0, DNA_SIZE * 2) # 随机选择变异点 child[mutate_point] = np.logical_xor(child[mutate_point], 1) # 反转变异点的基因 # 选择函数,根据适应度选择个体 def select(pop, fitness): idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True, p=(fitness / fitness.sum())) # 根据适应度比例选择个体 return pop[idx] # 打印信息函数,输出当前种群的状态 def print_info(pop): fitness = get_fitness(pop) # 计算适应度 max_fitness_index = np.argmax(fitness) # 找到最大适应度的索引 print("max_fitness:", fitness[max_fitness_index]) # 打印最大适应度 x, y = translateDNA(pop) # 转换DNA为坐标 print("最优的基因型:", pop[max_fitness_index]) # 打印最优个体的基因型 print("(x, y):", (x[max_fitness_index], y[max_fitness_index])) # 打印最优个体的坐标 print(F(x[max_fitness_index], y[max_fitness_index])) # 打印最优个体的函数值 # 程序的主执行部分 if __name__ == "__main__": fig = plt.figure() # 创建一个新的图形 ax = fig.add_axes(Axes3D(fig)) # 添加一个3D坐标轴 plt.ion() # 设置绘图模式为交互模式 plot_3d(ax) # 绘制3D曲面 pop = np.random.randint(2, size=(POP_SIZE, DNA_SIZE * 2)) # 初始化种群 for _ in range(N_GENERATIONS): # 进行N_GENERATIONS代进化 x, y = translateDNA(pop) # 转换DNA为坐标 sca = ax.scatter(x, y, get_fitness(pop), c='black', marker='o') # 在3D图上绘制当前种群 plt.show() # 显示图形 plt.pause(0.1) # 暂停0.1秒 pop = crossover_and_mutation(pop) # 交叉和变异操作 fitness = get_fitness(pop) # 计算适应度 pop = select(pop, fitness) # 选择操作,生成新的种群 print_info(pop) # 打印最终的种群信息 plt.ioff() # 关闭交互模式 plot_3d(ax) # 重新绘制3D曲面
代码解释 这段代码是一个遗传算法(Genetic Algorithm, GA)的实现,用于解决优化问题。遗传算法是一种启发式搜索算法,模仿自然选择的过程来找到问题的近似解。在这个例子中,算法的目标是寻找一个二维点 (x, y),使得给定的函数 F(x, y) 达到最小值。这个函数是一个典型的测试函数,称为香蕉函数(Banana Function),用于测试优化算法的性能。
以下是代码的主要组成部分及其功能解释:
初始化参数:定义了DNA的大小(DNA_SIZE),种群的大小(POP_SIZE),交叉率(CROSSOVER_RATE),变异率(MUTATION_RATE),进化代数(N_GENERATIONS),以及搜索空间的边界(X_BOUND 和 Y_BOUND)。
目标函数 F(x, y):这是需要优化的函数,输入是 x 和 y 坐标,输出是一个数值。遗传算法的目标是找到使这个函数值最小的 (x, y) 点。
绘图函数 plot_3d(ax):使用 matplotlib 库绘制目标函数的三维图形,帮助我们直观地理解函数形状和搜索空间。
适应度函数 get_fitness(pop):计算种群中每个个体的适应度。适应度是根据目标函数值来评估的,这里直接使用了目标函数 F(x, y) 的值。
DNA 转换函数 translateDNA(pop):将二进制编码的DNA转换为实数解(x 和 y 坐标)。这是通过将DNA中的每一位乘以2的相应幂次然后求和来实现的。
交叉和变异函数 crossover_and_mutation(pop):对种群中的个体执行交叉和变异操作。交叉是遗传算法中的一种操作,它模仿生物遗传中的交叉过程,通过交换父代的基因来产生新的后代。变异是另一种操作,它通过随机改变基因的值来引入种群的多样性。
选择函数 select(pop, fitness):根据个体的适应度来选择下一代种群。适应度更高的个体有更大的概率被选中。
打印信息函数 print_info(pop):输出当前种群中适应度最高的个体及其对应的 (x, y) 坐标和函数值。
主程序:初始化种群,然后进行多代进化。每一代都会计算种群的适应度,执行交叉和变异操作,然后选择新的种群。同时,会实时更新并显示当前种群在目标函数上的分布情况。
这段代码展示了遗传算法的基本流程,包括初始化、适应度计算、选择、交叉、变异和新一代种群的生成。通过多次迭代,算法逐渐找到使目标函数值最小化的解。这种方法在解决复杂的优化问题时非常有用,尤其是当问题的解空间很大或者目标函数难以直接优化时。
算法应用 若只有选择和交叉,而没有变异,则无法在初始基因组合以外的空间进行搜索,使进化过程在早期就陷入局部解而进入终止过程,从而影响解的质量。为了在尽可能大的空间中获得质量较高的优化解,必须采用变异操作。
交叉率的取值范围:一般为0.4~0.99,变异率的取值范围:一般为0.0001~0.1
终止条件 第一种:迭代次数 第二种:当目标函数是方差这一类有最优目标值的问题时,可采用控制偏差的方法实现终止。一旦遗传算法得出的目标函数值(适应度)与实际目标值之差小于允许值后,算法终止。 第三种:检查适应度的变化。在遗传算法后期,一旦最优个体的适应度没有变化或变化很小时,即令计算终止。
遗传算法的另一个重要参数是每代群体中的个体数。很明显,个体数目越多,搜索范围越广,容易获取全局最优解。然而个体数目太多,每次迭代时间也长。通常,个体数目可取100-1000之间。
应用领域
函数优化 函数优化是遗传算法的经典应用领域,也是遗传算法进行性能评价的常用算例。尤其是对非线性、多模型、多目标的函数优化问题,采用其他优化方法较难求解,而遗传算法却可以得到较好的结果。 组合优化。 随着问题的增大,组合优化问题的搜索空间也急剧扩大,采用传统的优化方法很难得到最优解。遗传算法是寻求这种满意解的最佳工具。例如,遗传算法已经在求解旅行商问题、背包问题、装箱问题、图形划分问题等方面得到成功的应用. 生产调度问题 在很多情况下,采用建立数学模型的方法难以对生产调度问题进行精确求解。在现实生产中多采用一些经验进行调度。遗传算法是解决复杂调度问题的有效工具,在单件生产车间调度、流水线生产车间调度、生产规划、任务分配等方面遗传算法都得到了有效的应用。 自动控制。 在自动控制领域中有很多与优化相关的问题需要求解,遗传算法已经在其中得到了初步的应用。例如,利用遗传算法进行控制器参数的优化、基于遗传算法的模糊控制规则的学习、基于遗传算法的参数辨识、基于遗传算法的神经网络结构的优化和权值学习等。 机器人 例如,遗传算法已经在移动机器人路径规划、关节机器人运动轨迹规划、机器人结构优化和行为协调等方面得到研究和应用。 图像处理 遗传算法可用于图像处理过程中的扫描、特征提取、图像分割等的优化计算。目前遗传算法已经在模式识别、图像恢复、图像边缘特征提取等方面得到了应用。 遗传算法的基本特征 智能式搜索 遗传算法的搜索策略,既不是盲目式的乱搜索,也不是穷举式的全面搜索,它是有指导的搜索。指导遗传算法执行搜索的依据是适应度,也就是它的目标函数。利用适应度,使遗传算法逐步逼近目标值。 渐进式优化 遗传算法利用复制、交换、突变等操作,使新一代的结果优越于旧一代,通过不断迭代,逐渐得出最优的结果,它是一种反复迭代的过程。 全局最优解 遗传算法由于采用交换、突变等操作,产生新的个体,扩大了搜索范围,使得搜索得到的优化结果是全局最优解而不是局部最优解。 黑箱式结构 遗传算法根据所解决问题的特性,进行编码和选择适应度。一旦完成字符串和适应度的表达,其余的复制、交换、突变等操作都可按常规手续执行。个体的编码如同输入,适应度如同输出。因此遗传算法从某种意义上讲是一种只考虑输入与输出关系的黑箱问题。 通用性强 传统的优化算法,需要将所解决的问题用数学式子表示,常常要求解该数学函数的一阶导数或二阶导数。采用遗传算法,只用编码及适应度表示问题,并不要求明确的数学方程及导数表达式。因此,遗传算法通用性强,可应用于离散问题及函数关系不明确的复杂问题,有人称遗传算法是一种框架型算法,它只有一些简单的原则要求,在实施过程中可以赋予更多的含义。 并行式算法 遗传算法是从初始群体出发,经过复制、交换、突变等操作,产生一组新的群体。每次迭代计算,都是针对一组个体同时进行,而不是针对某个个体进行。因此,尽管遗传算法是一种搜索算法,但是由于采用这种并行机理,搜索速度很高。这种并行式计算是遗传算法的一个重要特征。 参考资料 https://zhuanlan.zhihu.com/p/378906456